

It’s hard to imagine a modern society without telecoms networks. So, on the rare occasion when these networks go down, the impact is huge and keenly felt, both by the operator itself and by the public/consumer.
But the factors leading to such outages are on the increase. Extreme weather events, human errors, cybersecurity, or just plain old negligence when it comes to handling maintenance or construction are some common examples of networks outages. Telecoms networks are also much more likely to be attacked by hackers, of the criminal and the terrorist varieties. A recent analysis1 noted twelve cyber attacks on telcos in 2024, some of which affected more than one operator – for example, in July four networks in France suffered a major assault2 timed to coincide with the Paris Olympics.
Author: Laurence Carr, Regional Customer Solutions Director (APAC) at ng-voice
For operators, this means lost revenue from the calls not carried, increased churn by dissatisfied customers, and reputational damage. A half-day outage in November 2023 cost Australian telco Optus USD40m in direct lost revenues3, with knock-on effects on the financial results and share price of parent company SingTel. CEO Kelly Bayer Rosmarin resigned after the network outage.
Protecting against disasters and outages
A crucial component in the 5G network, which differs from its predecessors in being completely based on IP networking standards, is the IP Multimedia Subsystem (IMS). This is an architectural framework that allows the network to provide all those services that have their origins in the way that the circuit switched network functioned, but are now an important part of users’ expectations – such as voice and video calls, and text messages. If the IMS goes down then the network simply can’t deliver these services, even if other components are still working.
Historically network operators have adopted a two-pronged approach to protection, including: Geographic Redundancy, whereby multiple sites across the network are capable of handling its full capacity, so protecting against localised outages or site-specific failures; and Disaster Recovery (DR), intended to handle more catastrophic situations where either there is a failure of the core network or multiple sites simultaneously.
Public cloud: the modern solution for IMS disaster recovery
However, the traditional approach, of building a DR site within the network operator’s own premises, comes with prohibitive costs. Operators need to invest heavily in infrastructure, including hardware, Heating, Ventilation and Air Conditioning (HVAC), software licenses, and operational staff – all for a site which will only be used in emergencies, and won’t generate any revenue under normal circumstances.
Happily, for network operators, a cloud-based DR solution offers a compelling alternative, enabling them to reduce costs while ensuring service continuity. Public cloud is not only a new technology model but also a new business model, which enables scalability without a big upfront cost.
The public cloud has emerged as a modern and efficient solution for IMS disaster recovery, largely due to, IMS being less intensive on the data plane and the increasing adoption of cloud-native technologies in telecommunications. Unlike traditional infrastructure, which requires significant upfront CAPEX for hardware and network elements, the public cloud offers a cost-efficient alternative that can dynamically scale resources based on network traffic demand. This scalability allows operators to respond quickly to demand, handle outages while minimizing unnecessary expenses during normal operation.
With cloud-native IMS solutions, disaster recovery systems can scale dynamically in response to network traffic needs. By leveraging threshold-based autoscaling triggers and continuous monitoring of hardware and software KPIs, operators can scale resources in seconds, not hours, ensuring the network meets real-time traffic demands. This elasticity ensures the system can handle sudden increases in traffic, such as emergency communications, while keeping the operational footprint minimal in regular conditions to reduce costs.
Operators can realize significant Total Cost of Ownership (TCO) savings by adopting a cloud-based DR strategy. For instance, when there's no disaster, a small footprint IMS consumes minimal cloud resources. In the event of a disaster, the IMS system can scale up rapidly to handle peak loads. Since operators only pay for full capacity during the outage, the cloud model ensures cost efficiency—especially compared to traditional on-premises deployments, which require continuous investment in real estate, computing, networking, HVAC, and other infrastructure, regardless of usage.
Steps to building a cloud-based IMS for disaster recovery
Adopting a cloud-based approach to DR involves several sequential steps.
- Deploy a Secondary IMS in the Public Cloud
The first step involves setting up a secondary IMS in the public cloud alongside the operator’s primary IMS system. This secondary IMS can operate in parallel with the primary IMS system, even if provided by a different vendor.
Two key deployment options exist:
Option 1. A full mesh connection between the CSCF components (Call Session Control Functions) across both networks, which is a cleaner technical approach (Figure 1).
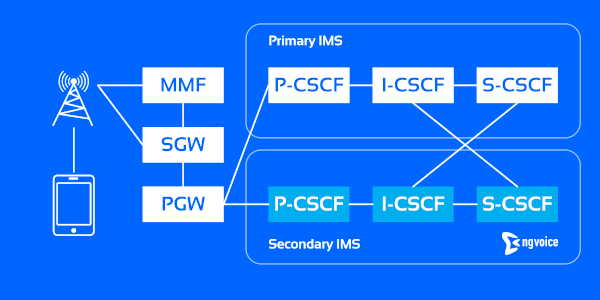
Figure 1: A full mesh connection.
Option 2. Breakout via the IBCF (Interconnection Border Control Function), which is simpler and more suited to brownfield deployments (Figure 2). In brownfield environments, this method is preferable due to complexities surrounding integration and ensuring service parity. However, in this approach, specific provisions must be made for subscriber re-routing to the DR IMS in case of a disaster.
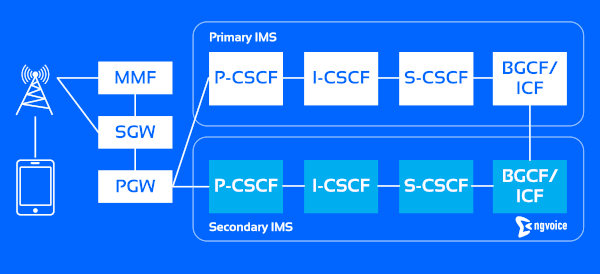
Figure 2: Breakout via the IBCF.
- Ensuring Traffic Flow to the Disaster Recovery IMS
Avoiding "dark outages"—where the DR system fails without detection—is crucial. One strategy to prevent this is by routing some live traffic (e.g., IoT or MVNO traffic) through the cloud-based IMS, either continuously or periodically, even during normal operations. This ensures the DR IMS remains functional and is regularly tested under real traffic conditions, thereby reducing the risk of discovering issues only during a crisis.
- Failover Mechanism During an Outage
In the event of a network outage, User Equipment (UE) will fail in its initial registration attempts and call setups, prompting the devices to attempt re-registration. At the same time, the PGW (Packet Gateway) detects the failure through health checks of the P-CSCF (Proxy-CSCF). As a fallback, the PGW provides the P-CSCF address of the DR IMS in the Protocol Configuration Options (PCOs) during UE re-attachment. This allows the UE to seamlessly register with the cloud-based IMS, ensuring minimal disruption.
- Handling a Registration Storm
A network outage will lead to a massive influx of registration attempts - a "registration storm." The cloud-based IMS must scale automatically to accommodate the surge in traffic (Figure 3). During this period, the system needs to prioritize emergency traffic while managing lower-priority traffic using overload handling mechanisms. For instance, lower-priority calls could be deferred using the Retry-After header, ensuring they are retried later, while higher-priority communications, such as emergency calls, are handled immediately. The randomization of registration expiry timers also ensures re-registration requests are spread over time, preventing future bottlenecks.

Figure 3: Scaling up to accommodate a “registration storm”.
- Fallback to Primary IMS
Once the issue causing the network outage is resolved, the system should gracefully transition traffic back to the primary IMS. This process includes rerouting calls and registrations while scaling down the cloud IMS to its minimal operational footprint, ensuring the cloud-based system is ready to scale up again if needed. The process to fall back to the primary IMS could be automatic, based on health checks/polling of the network, or it could be manual giving the operator full control.
Key choices for IMS disaster recovery
When planning an IMS disaster recovery (DR) solution, operators must balance technical and business factors to ensure their DR strategy meets operational needs without unnecessary complexity or cost. Here are the key considerations:
- Scope of Disaster Protection: Operators must determine the boundaries of their DR solution. Should it cover only the IMS (IP Multimedia Subsystem) or extend to other parts of the network like EPC/5GC (Evolved Packet Core / 5G Core), RAN (Radio Access Network), and associated services? For instance, adding a cloud-based EPC/5GC and HSS (Home Subscriber Server) could enhance the robustness of the DR site. In cases of RAN failure, domestic roaming agreements or VoWiFi (Voice over Wi-Fi) can provide additional failover options. This consideration defines the scope of services that need redundancy.
- Automation: Automating the failover process minimizes the risk of human error and speeds up recovery. This can involve core network health-checks, fallback routing, and auto-scaling mechanisms. However, operators must carefully test these automated processes to avoid false positives, where services are incorrectly rerouted, disrupting normal operations. A balance is needed between manual oversight and fully automated controls to ensure the right response in different disaster scenarios.
- Cloud Resource Requirements: When using public cloud infrastructure, sufficient networking and compute resources must be available during an outage, especially to handle the initial registration storm. Operators need to ensure their direct cloud connectivity (e.g., dedicated physical links between their network and the public cloud) has enough bandwidth and redundancy to support peak loads. Additionally, it's important to confirm the availability of cloud compute resources, to avoid delays or resource contention with other tenants in the public cloud.
- Impact on Ancillary Elements: Core components like the EPC, PCRF (Policy and Charging Rules Function), and Home Subscriber Server (HSS) must be considered when designing a DR strategy. During the disaster, the initial registration storm will trigger a significant increase in traffic towards these elements. To ensure uninterrupted service, operators must plan for this surge by deploying sufficient capacity for these ancillary components or ensuring they can scale automatically, like the IMS.
- Service Parity: Determining whether the DR IMS will provide full-service parity or focus on essential services is a major decision. Operators may decide that the DR solution should prioritize critical services like emergency calling, which requires fewer IMS components, compared to a full consumer offering that includes services like voicemail or online charging. A full DR system capable of offering every feature of the primary network may require complex integrations and higher costs.
- Phased Deployment Approach: To manage complexity and costs, operators can deploy a DR solution in phases. Initially, they can focus on a subset of services, such as emergency calling, and then gradually expand the scope to cover more services, introduce more automation, and add other network elements in subsequent phases. This incremental approach allows operators to build a scalable solution without overwhelming initial investments.
Conclusion: a flexible, scalable IMS for disaster recovery
Designing an effective disaster recovery IMS solution requires careful consideration of both technical and commercial aspects. The solution must be scalable, cost-effective, and robust enough to handle critical workloads, especially during crises when operational continuity is paramount.
At ng-voice we have developed a truly cloud-native, Hyperscale IMS Solution that is infrastructure-agnostic, cost-efficient and highly automated - designed for exceptional flexibility and scalability. Our containerized network functions can operate with minimal resource usage— serving 10’s of thousands of subscribers on as few as tens of virtual CPUs (vCPUs)—and can scale automatically to accommodate demands of thousands of vCPUs within minutes. This ensures operators are well-prepared for any disaster scenario, delivering operational continuity and peace of mind without the burden of large upfront investments or ongoing operational costs.
The integration of cloud-native technologies allows operators to leverage the full potential of public cloud infrastructure, reducing capital expenditures while enhancing service availability. Our solution not only meets the immediate needs of disaster recovery but also positions operators to adapt swiftly to future challenges and opportunities.
Sources
1 “12 recent cyber-attacks on the telco sector”, Wisdiam, 31 July 2024.
2 “French internet cables cut in act of sabotage that caused outages across country”, The Register, 29 July 2024.
3 “Optus network crash cost the company $40M”, Light Reading, 23 February 2024.
Laurence Carr is the Regional Customer Solutions Director (APAC) at ng-voice, with over 14 years of experience in voice networking, IMS and cloud technologies. Drawing on his tenure at Metaswitch and Microsoft within Azure for Operators, Laurence brings deep technical expertise and strategic insight to the evolving landscape of cloud-native telecommunications, where he now focuses on driving adoption of ng-voice's innovative containerized IMS solutions across the APAC region.






